
The 5 rules of A/B testing
If you are in an online business, most probably, you know what A/B testing is. (Sometimes it’s called split testing or bucket testing). And there is a big chance, that you have already done at least some headline or e-mail subject tests. Regardless you are an online marketer, web designer, product manager, data analyst or UX-expert you can easily set up and run A/B-tests all around your website and product. And this is cool. BUT!
Even if most people know A/B-testing, the majority of them are doing it wrong, because they are breaking some of these 5 simple rules! Go through on them and make sure you won’t do the same mistakes!
What A/B testing is? The basics.
A good research project has 4 steps:
- Qualitative Research
- Data Research
- AB-testing
- Implementation
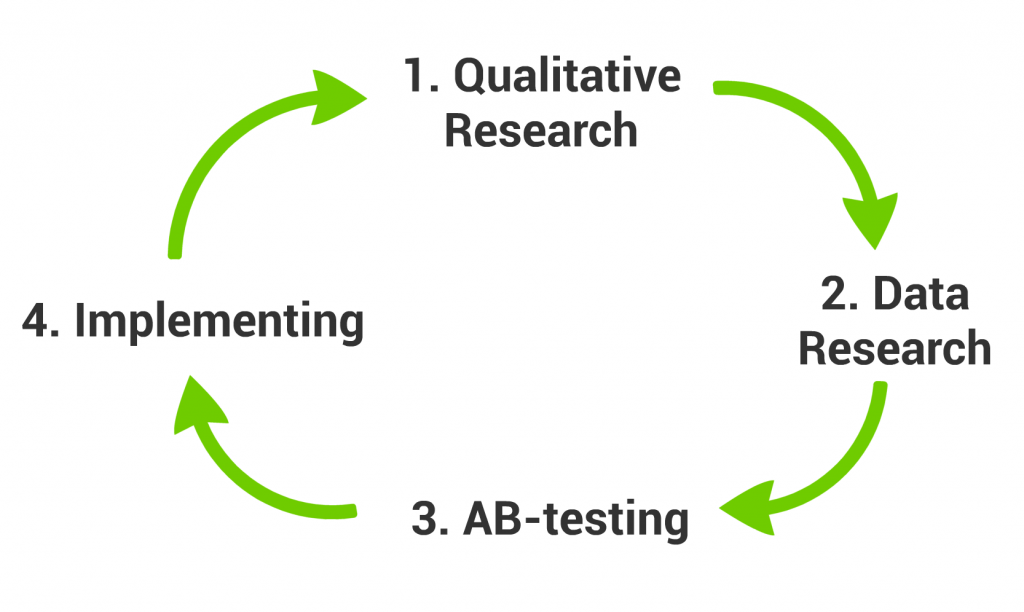
Qualitative Research –» Data Research –» AB-test –» Implement –» Repeat
Qualitative Research helps you to identify the issue, Data Research helps you to validate the issue and eventually A/B-testing helps you to compare the different resolutions to each other. (I wrote about this in details here: Create a Good Data Research Plan!)
AB-testing is a research method, where you compare two different variations of your website to each other. You do this by a randomized experiment, where 50% of your visitors get the “A” version of your site, 50% get the “B” version of your site. You measure the conversion for each “A” and “B” groups. And the more successful variation wins.

Two different “Sign Up” buttons — ready to A/B testing
You can A/B test not only your website, but your ads, your e-mails, your e-mails’ subjects, your mobile app, your features, even your pricing… anything. And yes, you can have more than 2 variations (3, 4, even 10) in an experiment.
If you don’t know, Why A/B testing is needed at all? Read it here: Click.
Rule #1: The different versions should run at the same time!
Running version “A” in November, then running version “B” in December is NOT an A/B test! Why? Because of seasonality.
Imagine that you are an online book store, it’s very likely that by default you will have a higher-than-average conversion rate in December (because everyone buys Christmas presents in that month) and a lower-than-average conversion rate in January (because everybody got their books already at Christmas). If you test the colours of your “BUY” buttons during this period, like:
- test blue during November,
- test green during December,
- test red during January,
you won’t be able to tell if the change was the effect of the actual colour-change or just the seasonality.
In a proper A/B test the different versions are running at the same time, in parallel with each other.
In a proper A/B test the different versions are running at the same time, in parallel with each other.
Rule #2: The test and the control group should be selected randomly!
I give you a classic “AB-testing” mistake example:
Ben (fictional character) works for a startup. He creates a new personalized newsletter for all the website visitors, who filled the optional fields (eg. gender, current city, education level) on the registration form. This group will be Ben’s “test group”. He compares this personalized newsletter to a general newsletter. The general newsletter will be sent for the rest of the audience, who didn’t fill the optional fields on the reg-form. They will be the “control group”. After running the campaign Ben sees that the personalized newsletter has a 3-times higher click-through-rate. Wow! Personalization is awesome, right?
Well. No. I mean, maybe. But the click-through-rate would have been higher for the test group anyway, because they are more committed visitors. We know this from the fact, that they gave us more data about themselves.
This was NOT an A/B test! This was something called selection bias.
To avoid these kind of issues, make sure that the test and the control groups are as homogeneous as they can be. To achieve this, you should have 2 things: a) random selection and b) big enough sample size.
Rule #3: Don’t let the Users know they are taking part in the experiment
Another kind of bias is the observer bias. I see time-to-time websites “AB-testing” with putting up two variation of their website to the front page, where as a visitor you can select, which one you want to see. And they make their conclusions by checking, which version people choose. This is NOT an A/B test, either!

I’m pretty sure that Rolling Stones didn’t mean this to apply for user experience design, though it’s still valid for that too. Your users don’t know what they need. So if you ask them, you might get honest, but misleading answers. Don’t listen to what your users say. Listen to how your users act! You need to discover the perfect user experience by analyzing data and testing hypotheses, not by surveys. So don’t let users know, that they are in an A/B test.
Rule #4: Define measurable goals before the experiment and select one key-metric!
An experiment can’t run without a measurable goal.
Just set up and track multiple things! You can compare your different variations by engagement, click-through-rates, conversion rates, page views, time spent on page, etc. It’s always good to see all these metrics, because you can learn from them.
But when it comes to evaluate the experiment, you should have only one success metric. You will use this metric to make your decision. Eg. if conversion rate is higher for version A, than B, then version A won. If B is higher, than version B won. Simple as that.
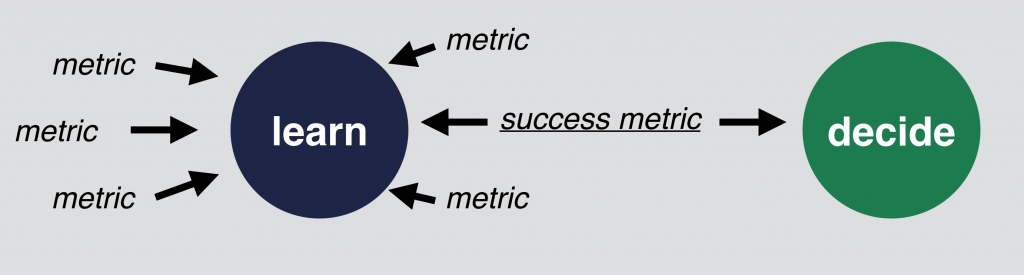
Select one success metric!
This success metric should be selected before you start your test. The easiest way to lie to yourself with data, if you set up 10 different goals for an A/B test, then after the experiment you pick only the numbers, that are proving your hypothesis and ignore those, that are not. You can easily prevent it, if you select your most important metric beforehand and you strictly use that number for the evaluation.
Rule #5: Before evaluation look at significance level!
If you are using Optimizely (which is by the way my preferred “A/B-testing as a Service” tool as well), you can see the results as something like this:
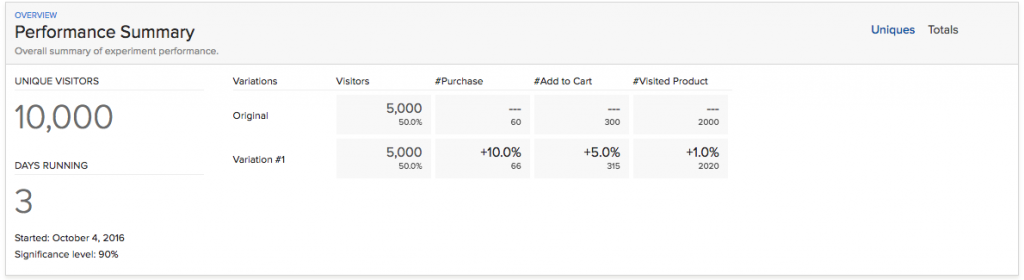
Optimizely + A/B testing (significance level)
Unfortunately 4 out of 5 Optimizely users (that’s what I’ve experienced) are evaluating these results as a success. But it is not! Yet at least. Before you look at your conversion rate, always look at significance level first! If your significance is under 1%, then it doesn’t really matter that you have 30% uplift on your “B” version. You need to wait for more data to come in, because most probably you just had a lucky day.

Check the significance level first! (right bottom corner)
If you flip a coin 10 times, it can happen, that you will have 9 heads and 1 tails. But it doesn’t mean that the probability of getting head is 90% and tail is 10%. It only means, that your sample size is too low. If you flip the coin 1000 times, you will have a higher chance to have something around 50-50%.
The same thing happens at A/B testing. You need to wait for a significant sample size to have conclusive results and a great decision.
How big is the optimal sample size? How to measure significance easily? Find in this earlier article of mine: Significant or not? Measure the efficiency of your A/B test!
The same thing happens at A/B testing. You need to wait for a significant sample size to have conclusive results and a great decision.
How big is the optimal sample size? How to measure significance easily? Find in this earlier article of mine: Significant or not? Measure the efficiency of your A/B test!
+1 Rule #6: Change one thing at a time!
Well, this is not necessarily a real rule. But one’s for sure: if you change one thing at a time, it will be much easier to identify the reason of the conversion rate increase. On the other hand sometimes changing only one thing can slow you down. There are cases, where you need more radical changes, than just simply fine-tuning your headline message. In these cases you can take the risk of changing everything (layout, colors, messages). This risk has two components:
A) Maybe your new version is gonna be too radical and even if you put a lot of work into that, it will bring worse results, than the original version. Then it was sort of waste of your time.
B) Your new version performs better, but you won’t be able to understand, that which exact changes brought the great result.
Either way, if you have great analysts and UX people on your team, they can minimize the risk of A) and the risk of B) as well – by analyzing and understanding the different versions using other methods, than A/B testing (eg. UX researches, data analysis, heat mapping, predictive analytics, 5-sec tests, etc.).
So I’d say, don’t be afraid to change more than one thing, if it’s needed. But if you have the luxury of time and you just want to fine-tune things step-by-step, then I suggest to change things one-by-one.
Conclusion
A/B testing is a great tool and it’s even better if you are doing it right! 😉 So please keep these 5+1 rules and if you know someone who doesn’t, let him/her know, what to change!
Original Article rights :
Written by Tomi Mester on December 16, 2016 checked and researched by Kalim Khan (khanztuto).(khanzdevelopers) For educational and research purposes only. Funkada is doing free website audit/analysis and working on research and implementation of CRO in Malaysia.
There is an amazing new opportunity that is growing in popularity online.
ReplyDeleteBig companies are paying people just for sharing their opinions!
You can earn anywhere up to $5 - $75 per each survey!
This is available to anybody from any country!